
How does LLM streaming works
A behind-the-scenes look at how large language models and backend systems deliver responses token by token—creating real-time, conversational experiences.


What is LLM Streaming?
LLM streaming is a technique that enables incremental reception of data as it's generated by a large language model, rather than waiting for the entire response to be completed before sending it to the client.
Think of it like watching a live broadcast versus waiting for a pre-recorded message - you see the content as it's being created.

Real-World Example: ChatGPT
ChatGPT is a prime example of LLM streaming in action, where users can watch responses being typed out word by word, creating a more interactive and engaging experience.
Why is Streaming Important?
Streaming significantly enhances user experience by:
Reducing perceived wait times for next tokens from LLM.
Allowing users to see responses being generated in real-time.
Enabling early interruption if the AI isn't heading in the desired direction.
Optimizing costs by preventing unnecessary token generations.
The Dissection using the first principles
To understand the LLM streaming, we need to dissect it at three levels:

Frontend Perspective: How does ChatGPT UI stream content to user.
Backend Perspective: How does backend supports LLM streaming.
AI Perspective: How does LLM supports token generation for LLM Streaming.
Let’s dive in…
How does backend support LLM streaming 🤔
When it comes to backend, everything boils down to the client-server architecture and we need to understand how content can be streamed at the the request response level.
There are three main approaches to implement streaming in a client-server architecture:
Chunk Encoding
Server-Sent Events (SSE)
WebSockets
To explore each approach in detail, we will try to understand the networking protocol, how FAST API server implements that protocol and how data flows back to react.
Understanding Chunk Encoding 🚀
Imagine you're sending a very long letter, but instead of waiting to write the entire letter, you send it page by page as you write it. That's essentially what chunk encoding does in the digital world. It's a method introduced in HTTP/1.1 that allows data to be sent in pieces (chunks) rather than all at once.
Let's break down the process step by step:
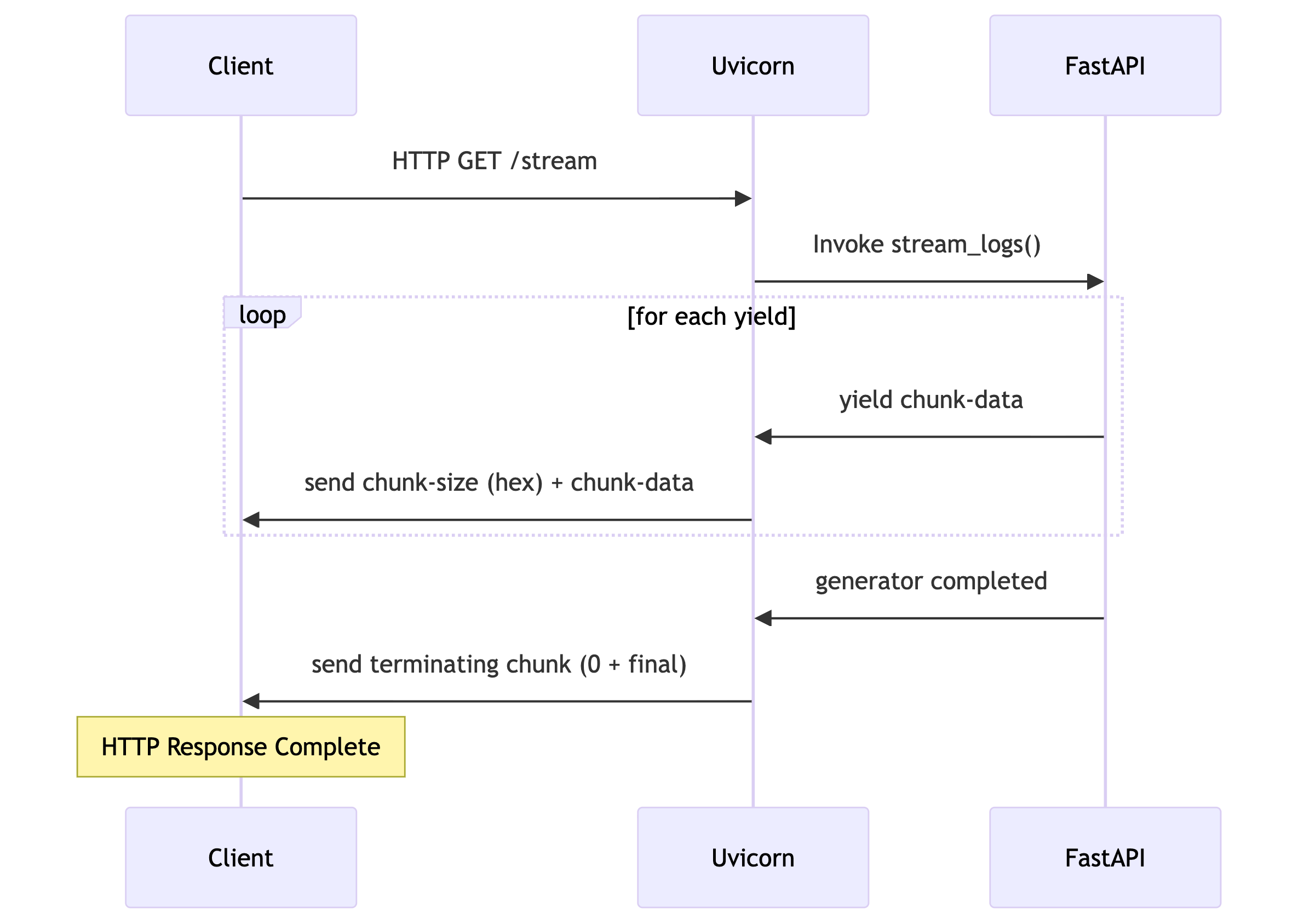
Initial Setup : The server (In the above case FAST API) first sends the below response headers to tell the client "Hey, I'm going to send you data in chunks!". This helps make sure request from client does not gets marked complete on first chunk.
HTTP/1.1 200 OK
content-type: text/plain; charset=utf-8
Transfer-Encoding: chunked Chunk Format : Each chunk follows this structure:
[Size of chunk in hexadecimal]\r\n
[Actual chunk data]\r\n
Example:
11\r\n
Developer Network\r\n
7\r\n
Mozilla\r\nFast API Implementation:
Fast API has a response type that takes care of setting up the above response header. This response type is called as StreamingResponse.
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import time
app = FastAPI()
def number_generator():
for i in range(10):
time.sleep(1) # Simulate processing time
yield f"Number {i}\n"
@app.get("/stream")
def stream_numbers():
return StreamingResponse(number_generator(), media_type="text/plain")Curl response :
curl http://localhost:8000/stream
Number 0
Number 1
Number 2
...
Number 9Do you know that, Sagemaker uses chunk encoding to expose streaming responses for ML endpoints. Check out this Blog: https://aws.amazon.com/blogs/machine-learning/elevating-the-generative-ai-experience-introducing-streaming-support-in-amazon-sagemaker-hosting/
Understanding Server Side Events (SSE) 🚀
Server-Sent Events (SSE) is a technology that enables servers to push real-time updates to clients over a single, long-lived HTTP connection. Think of it as a one-way communication channel where the server can continuously broadcast information to the client.
Let's break down the process step by step:
Client Request: Client first send the request saying that it is looking for the events at `/events` and is ready to accept the data as event-streams.
// Client Request
GET /events HTTP/1.1
Accept: text/event-streamServer Response : The server (In the above case FAST API) first sends the below response headers to tell the client "Hey, I'll send you data as a stream of events". This helps make sure request from client does not gets marked complete on first event and makes it a long lived connection.
HTTP/1.1 200 OK
Content-Type: text/event-stream
Cache-Control: no-cache
Connection: keep-aliveFast API implementation:
from fastapi import FastAPI
from sse_starlette.sse import EventSourceResponse
import asyncio
app = FastAPI()
@app.get("/stream")
async def stream():
async def event_generator():
while True:
yield {"data": "Hello! This is a server update"}
await asyncio.sleep(2) # Send update every 2 seconds
return EventSourceResponse(event_generator())Curl Response:
curl -N -H "Accept: text/event-stream" http://localhost:8000/stream
data: Hello! This is a server update
data: Hello! This is a server update
data: Hello! This is a server updateUnderstanding Websockets 🚀
WebSocket is like having a phone conversation where both parties can speak at any time. It's more complex but offers greater flexibility. This is usually used in Chat Applications.
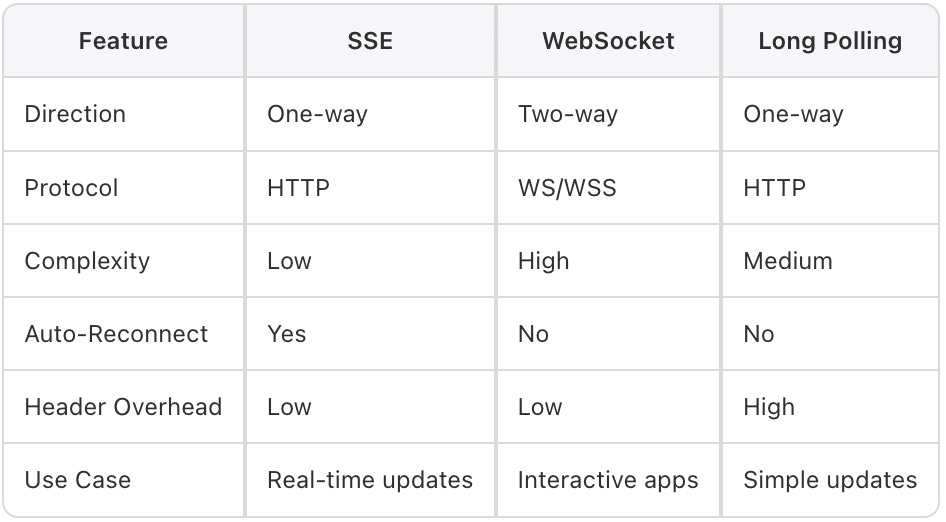
Comparison of 3 approaches:
Dance of tokens: How LLMs stream their thoughts 🤔
When you see an AI chatbot responding to you word by word, what's happening behind the scenes is a fascinating interplay between the LLM's token generation and the backend's streaming capabilities. We have already covered how backend supports streaming capabilities above.
Let's understand this dance of tokens generated by LLM that makes real-time AI interactions possible.
The Token Generation Process
At its heart, an LLM thinks in tokens, not words. When you send a prompt, the model begins what's called autoregressive generation – a fancy term for predicting one token at a time, each prediction influenced by what came before it. Imagine someone writing a story, but instead of thinking about the whole sentence at once, they're deciding each word based on what they've written so far.
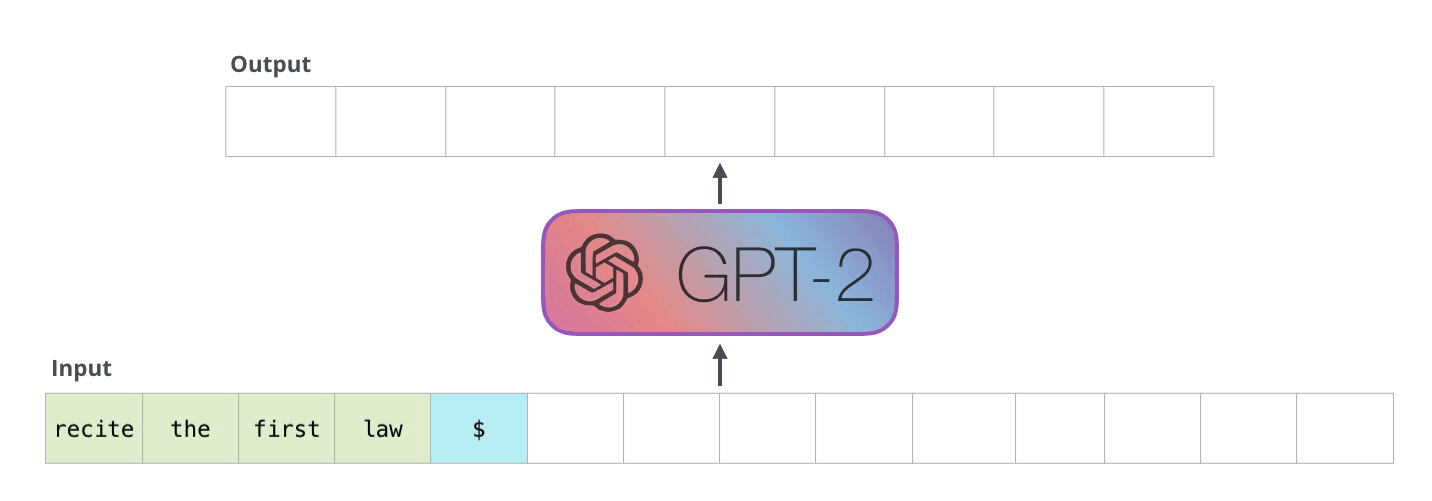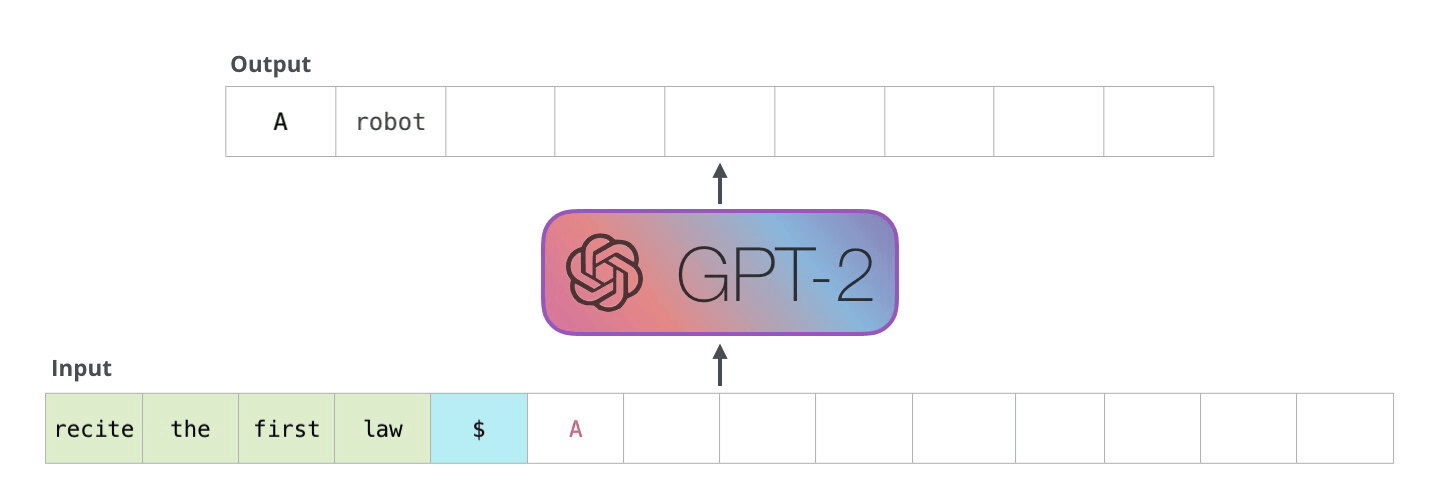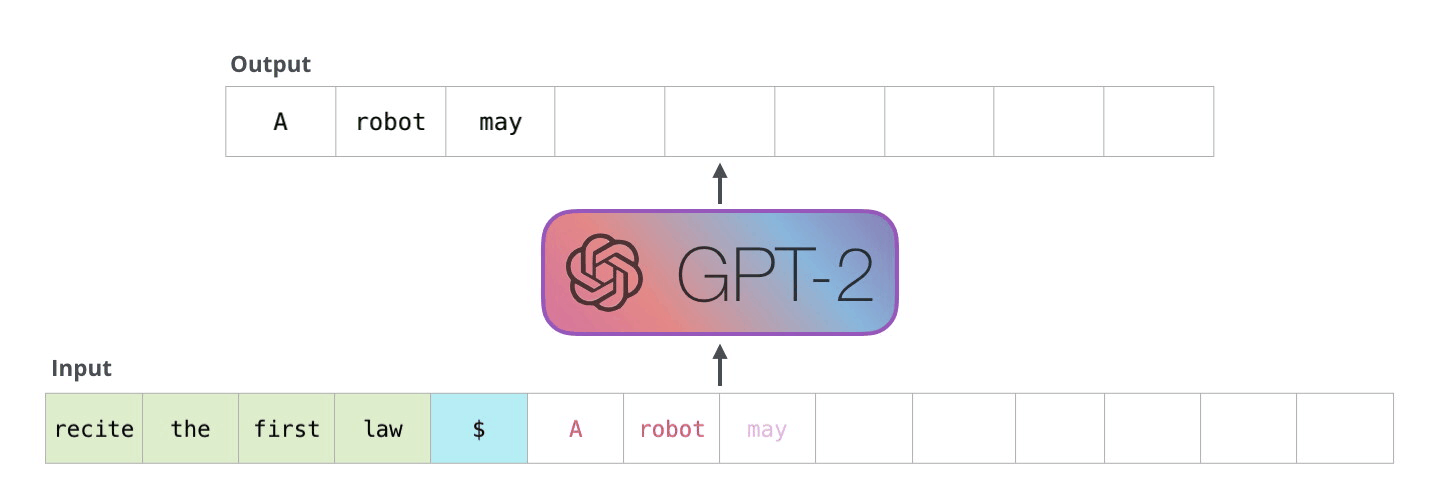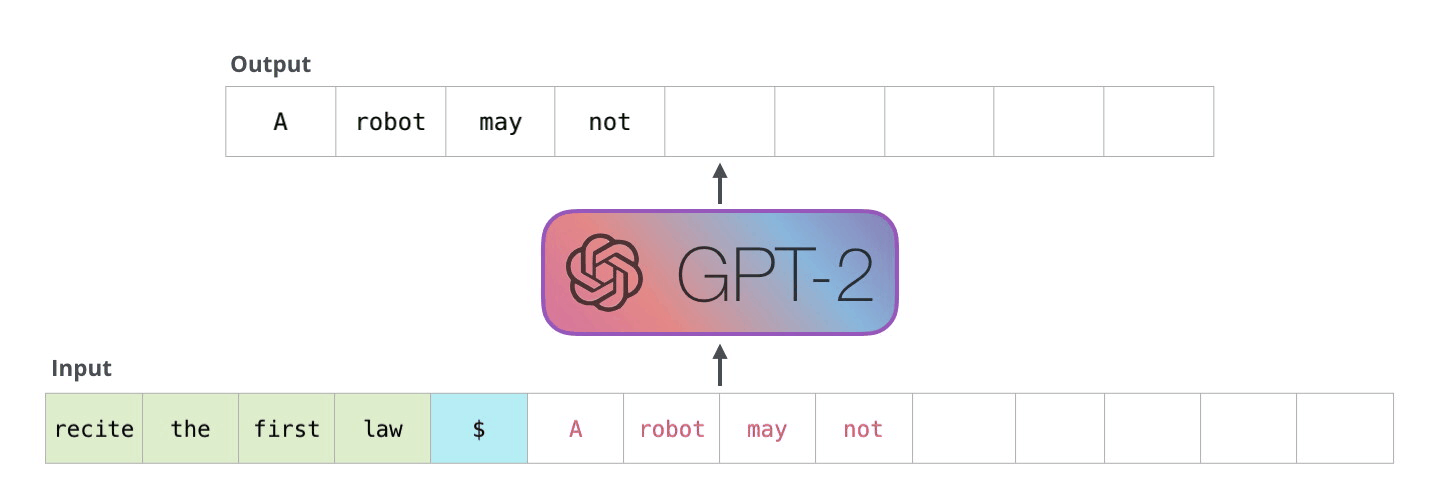
The process is sequential and methodical. The model looks at your input, generates a probability distribution over its entire vocabulary, and selects the most likely next token. This could be a full word like "hello" or just part of a word like "ing" or "pre". Each token is a building block that contributes to the final response.
These tokens are what streamed using APIs implemented by OpenAI, Anthropic AI etc. Players like OpenAI, Anthropic AI uses one of the 3 approaches shared above for their backend implementations to stream content.
References: 📖
Open AI Streaming completion in Python
Possible Llama Opensource implementation for handling streaming of tokens
 | A guest post by
|