
7 Asks from ML Engineers That Define MLOps
What ML engineers actually need to keep models alive in production - from chapter 1 of Building Machine Learning Systems with a Feature Store


Introduction
If you’ve ever shipped an ML model to production, you know the real work starts after the Jupyter notebook looks good.
Training a model is one thing. Keeping it alive, reliable, and improving in production is a completely different game. That’s where MLOps comes in — and at its core, MLOps is really about answering the asks that ML engineers have been making for years.
Jim Dowling, in Chapter 1 of his book Building Machine Learning Systems with a Feature Store, lays out these asks beautifully. I’m paraphrasing and expanding on them here because I think every ML and platform engineer should internalize these principles early.

1. Testing with Minimal Friction
MLOps folks believe that testing should have minimal friction on your development speed.
If running your tests is painful, you won’t run them. It’s that simple. The goal is to automate test execution so it becomes invisible — tests run every time you push code, and you only hear about them when something breaks. Popular CI platforms like GitHub Actions, Jenkins, and Azure DevOps make this straightforward. But here’s the thing — CI is not a prerequisite for starting to build ML systems. If you come from a data science background, comprehensive testing might be unfamiliar territory, and that’s completely fine.

Start small:
Unit tests for your feature transformation functions
Model performance and bias tests in your training pipelines
Integration tests for your end-to-end ML pipelines
The key insight is this: you can add automated tests after you’ve validated that your MVP is worth maintaining. Don’t let perfect testing be the enemy of shipping.
2. Continuous Deployment (CD)
MLOps folks love that feeling when you push changes in your source code and your ML artifact or system is automatically deployed.
Deployments typically flow through three environments:
Dev — where you build and experiment
Preprod — where you test with realistic conditions
Prod — where your model meets the real world
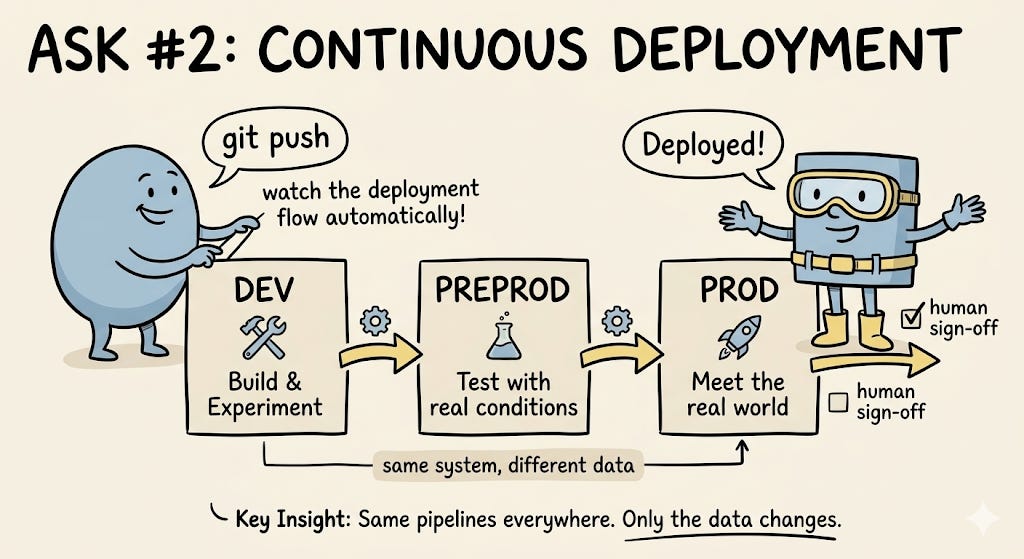
Although a human may ultimately sign off on deploying an ML artifact to production, every step leading up to that decision should be automated. That’s continuous deployment.
An important philosophy: your whole ML system — feature pipelines, training pipelines, inference pipelines — should be buildable, testable, and runnable in any of these environments. The only thing that changes is the data your system can access. Dev might not have production data, and that’s expected.
3. Data Quality - “Garbage In, Garbage Out”
This is the oldest maxim in the database community, and MLOps folks live by it.
Many ML systems ingest data that has few or no guarantees on its quality. And here’s the brutal truth: blindly ingesting garbage data leads to very well-trained models that still predict garbage. Your loss curves look great, your metrics pass, but your model is confidently wrong.

The fix is data validation — designing explicit tests for your feature pipelines that catch problems before they reach your model:
Is the data in the expected schema?
Are there unexpected null values or outliers?
Has the distribution shifted in a way that signals something is wrong?
Just as importantly, you need to define mitigating actions — what do you do when data is identified as incorrect, missing, or corrupt? Do you halt the pipeline? Fall back to a cached version? Alert the data team?
4. Versioning & Rollback
MLOps folks dream of a big green button for upgrading the system and a big red button for rolling back a problematic upgrade.
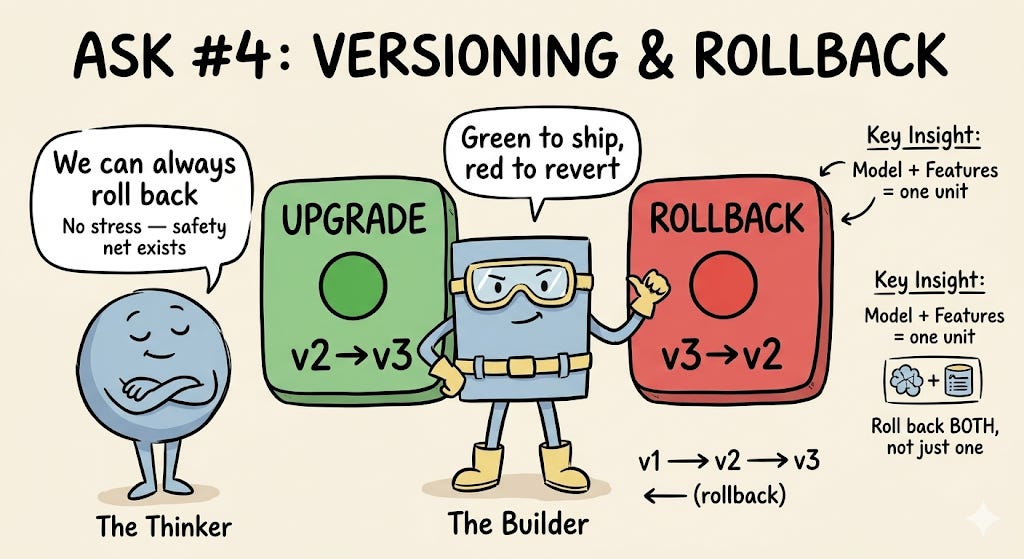
This isn’t just a nice-to-have — it’s a prerequisite for doing anything safely in production. Versioning both features and models enables:
A/B testing — run two model versions side by side to measure impact
Safe upgrades — deploy a new version with confidence
Instant rollback — when something goes wrong, revert to the last known-good version of both the model and the features that feed it
The key word here is both. Rolling back a model without rolling back the features it was trained on is a recipe for subtle, hard-to-debug failures. Your versioning strategy needs to treat the model and its feature dependencies as a unit.
5. Evals for LLMs & Agents
MLOps folks don’t like surprises — especially the kind where a new version of your LLM or agent introduces unexpected behavior.
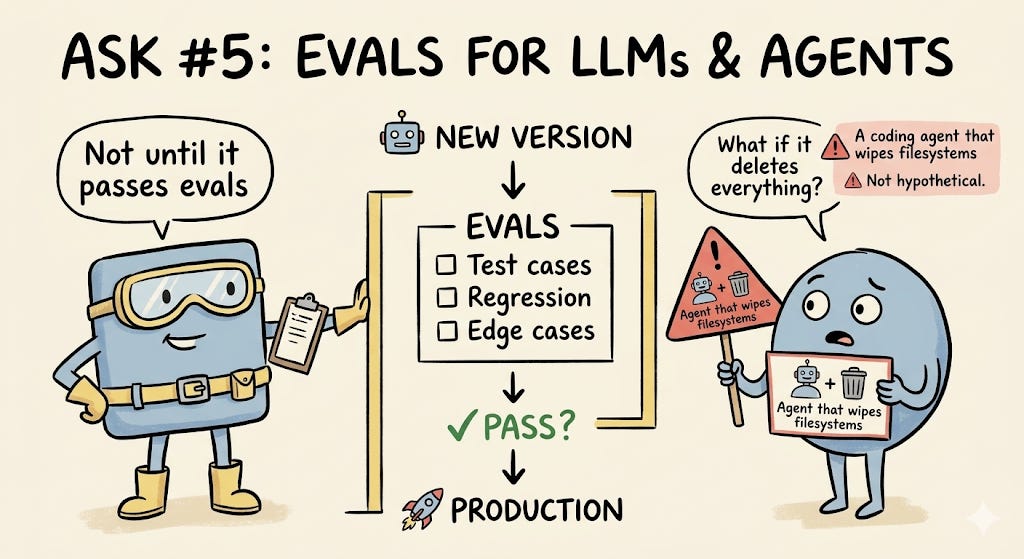
This is a newer ask, born from the era of large language models and AI agents. Traditional ML had model performance metrics. But LLMs and agents are different beasts — their failure modes are more open-ended, harder to predict, and potentially more dangerous.
Consider: a version of a coding agent that could wipe users’ filesystems clean. That’s not a hypothetical — that’s the kind of risk that makes evals essential.
Before any LLM application or agent goes into production, you need to design and run evaluations that stress-test the changes. This means:
Defining a suite of test cases that capture expected behavior
Measuring regression on known-good outputs
Testing edge cases and adversarial inputs
Evals are to LLMs what unit tests are to traditional software — except the stakes are often higher and the behavior is less deterministic.
6. Monitoring & Observability
MLOps folks love to know how their systems are performing.
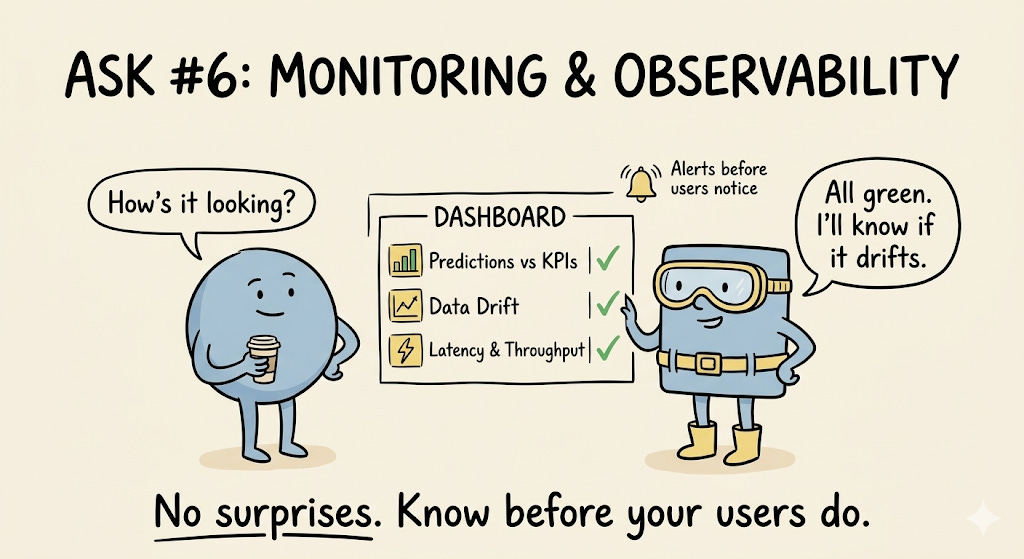
A production AI system isn’t a “deploy and forget” artifact. It’s a living system that needs continuous observation. At minimum, you should be collecting metrics and building dashboards for:
Model prediction quality — How are your predictions tracking against business KPIs? A model can be technically accurate but commercially useless if it’s optimizing the wrong thing.
Data drift — Is the incoming data still resembling what you trained on? Distribution shifts happen quietly and can degrade model performance without any code changes.
Platform performance — What’s the throughput and latency of your model serving, feature store, vector index, and ML pipelines? A model that takes 2 seconds to respond in a system with a 200ms SLA is a broken model.
The goal is simple: no surprises. When something degrades, you should know about it before your users do.
7. Logging for Debugging
MLOps folks need logs from operational services to debug and improve AI systems.

This might sound basic compared to the other asks, but logging in ML systems is uniquely important. In traditional software, logs help you trace errors. In ML systems, logs help you understand why your model is wrong.
For LLMs specifically, eyeballing model logs is a surprisingly powerful technique for error analysis. Looking at actual inputs and outputs — not just aggregate metrics — often reveals patterns that no automated metric would catch.
For classical ML systems, logs are equally critical for debugging errors and understanding model performance in production conditions that your test environment couldn’t fully simulate.
The Bottom Line
These asks aren’t a checklist to implement on day one. They’re a north star — the set of capabilities that mature ML teams converge toward as their systems grow in complexity and criticality.
If you’re just starting out, pick the ones that hurt the most and address those first. If you’re already running ML in production, use this list to identify gaps.
The common thread across all seven asks? Reduce surprises in production. That’s really what MLOps is about.
Inspired by Chapter 1 of Jim Dowling’s “Building Machine Learning Systems with a Feature Store” (O’Reilly, 2025).
 | A guest post by
|